What is AWS Glue and how Can It Benefit My Business?

What is AWS Glue?
AWS Glue is an event-driven, server-less computing platform, part of the Analytics group of services from Amazon Web Services. It is a fully managed ETL service that can extract data from various sources, transform it into a desired format, and load it into a target data store. It can handle a variety of data formats, including unstructured data, semi-structured data, and structured data. AWS Glue supports both batch and streaming data ingestion modes, making it suitable for a wide range of data integration scenarios. AWS Glue is a great tool for data engineering due to its scalability, reliability, and cost-effectiveness.
AWS Glue consists of three main components:
Glue ETL jobs: These are the ETL jobs you create and run in AWS Glue. You can create Glue ETL jobs using either Python or Scala or the Glue ETL library and the Glue ETL job developer guide.
Glue Data Catalog: This is a central repository that stores metadata information about data stored in various data stores. The Glue Data Catalog can be accessed from other AWS services, such as Amazon Redshift, Amazon Athena, and Amazon EMR, to discover and access data stored in various data stores.Glue development endpoint: This is a development environment that you can use to develop, debug, and test your Glue ETL jobs. You can connect to a Glue development endpoint using a remote desktop connection or using a notebook, such as Amazon SageMaker notebooks or Jupyter notebooks.
AWS Glue Features and Benefits
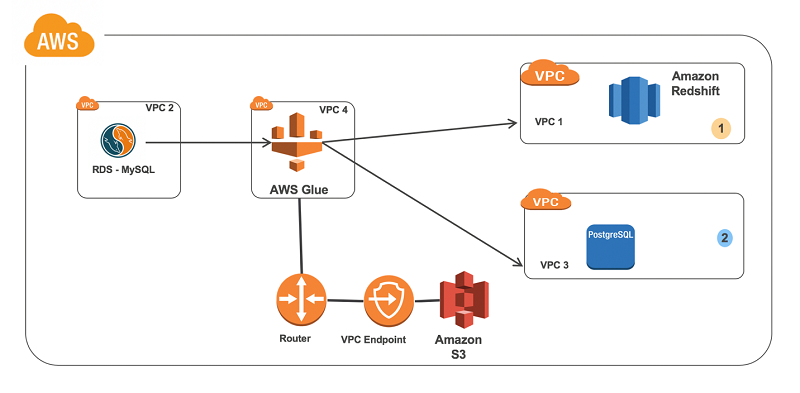
AWS Glue has several features and benefits that make it an ideal choice for ETL workflows.
Fully managed service: AWS Glue is a fully managed service, which means that you don’t have to worry about managing and scaling the infrastructure or installing and maintaining software. AWS Glue automatically scales up or down based on the workload, and you only pay for the resources you use.
Data Integration: AWS Glue can extract data from various data sources, such as Amazon S3, Amazon Redshift, Amazon RDS, and Amazon DynamoDB, and transform it into a desired format. It supports various data formats, such as CSV, JSON, Avro, and Parquet, and can convert data between these formats.
Data Catalog: The Glue Data Catalog is a central repository that stores metadata information about data stored in various data stores. It can be accessed from other AWS Services, such as Amazon Redshift, Amazon Athena, and Amazon EMR, to discover and access data stored in various data stores.
Data Classification: AWS Glue can automatically discover and classify data stored in various databases and add the metadata information to the Glue Data Catalog. This can save you time and effort in manually classifying and cataloging your data.
ETL jobs: AWS Glue ETL jobs are the core building blocks of AWS Glue. You can create ETL jobs using Python or Scala, or using the Glue ETL library and the Glue ETL job developer guide. You can also use the Glue development endpoint to develop, debug, and test your ETL jobs before deploying them to production.
Data pipelines: AWS Glue can orchestrate and maintain data pipelines or as we call it within AWS environment data workflows, that extract data from various sources, transform it, and load it into a target data store. You can use the AWS Management Console or the AWS Glue API to create, edit, and delete data pipelines.
Serverless architecture: AWS Glue is built on a server-less architecture, which means that you don’t have to worry about provisioning and managing servers. You only pay for the resources you use, and AWS Glue automatically scales up or down based on the workload.
Security and compliance: AWS Glue follows industry-standard security practices, including encryption of data in transit and at rest and access controls. It is also compliant with various regulations, such as HIPAA, PCI DSS, and GDPR.
Use Cases for AWS Glue
AWS Glue can be used in a variety of ETL scenarios, such as:
Data Lake integration: AWS Glue allows for the extraction of data from a variety of sources, including Amazon S3, Amazon Redshift, Amazon RDS, and Amazon DynamoDB, and load it into a Data Lake stored in Amazon S3. You can use AWS Glue to transform and clean the data, and to partition and optimize the data for querying and analysis.
Data Warehouse integration: AWS Glue enables data extraction from various sources, including but not limited to Amazon S3, Amazon Redshift, Amazon RDS, and Amazon DynamoDB, and loads it into a Data Warehouse stored in Amazon Redshift. You can use AWS Glue to transform and clean the data, and to optimize the data for querying and analysis.
Data Lake and Data Warehouse integration: AWS Glue can extract data from various data sources, and load it into both a Data Lake and a Data Warehouse stored in Amazon S3 and Amazon Redshift, respectively. You can use AWS Glue to transform and clean the data, and to partition and optimize the data for querying and analysis.
Data migration: AWS Glue data extraction capabilities cover a wide range of sources, such as Amazon S3, Amazon Redshift, Amazon RDS, and Amazon DynamoDB, and load it into a target data store. You can use AWS Glue to transform and clean the data, and to migrate the data from one data store to another.
Stream processing: AWS Glue can extract data from streaming data sources, such as Amazon Kinesis Streams and Amazon Managed Streaming for Apache Kafka (Amazon MSK), and transform and load it into a target data store. You can use AWS Glue to process and analyze streaming data in real-time, and to build real-time dashboards and alerts.
How to Set Up and Use AWS Glue
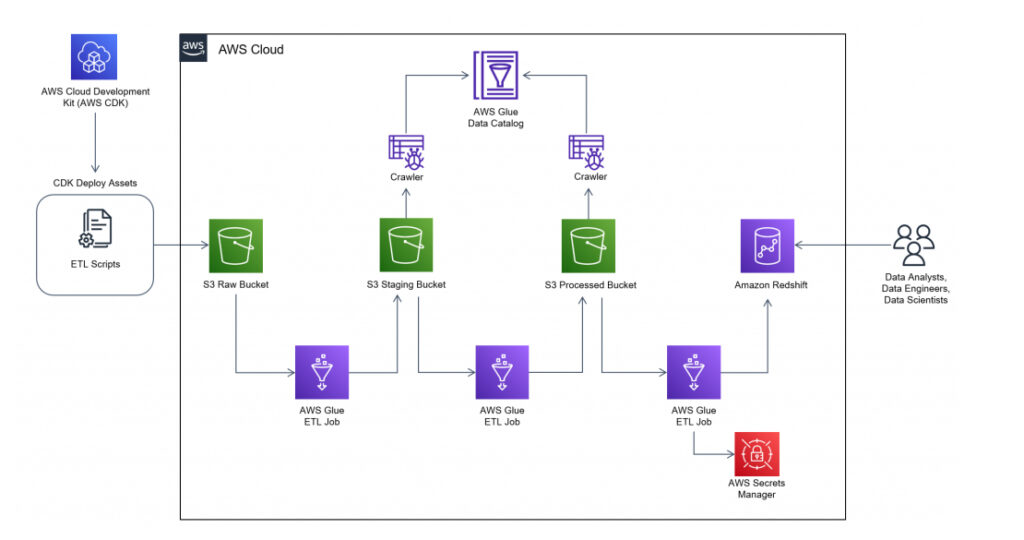
To set up and use AWS Glue, you need to perform the following steps:
- Create an AWS Glue Data Catalog: The first step is to create an AWS Glue Data Catalog, which is a central repository that stores metadata information about data stored in various data stores. You can create an AWS Glue Data Catalog by going to the AWS Management Console and navigating to the Glue service.
- Connect to data sources and targets: The next step is to connect to your data sources and targets, such as Amazon S3, Amazon Redshift, Amazon RDS, and Amazon DynamoDB. You can use the Glue ETL library and the Glue ETL job developer guide to connect to these data stores using the appropriate connectors. You can also use the Glue development endpoint to test and debug your connection to the data sources and targets.
- Create an ETL job or Data pipeline: Once you have connected to your data sources and targets, you can create an ETL job or data pipeline to extract, transform, and load the data. You can use the AWS Management Console or the AWS Glue API to create an ETL job or data pipeline.
- Set up scheduling and triggers: You can set up scheduling and triggers to run your ETL jobs or data pipelines on a regular basis, or in response to certain events. For example, you can schedule your ETL job or data pipeline to run daily, weekly or monthly or trigger it to run when new data is added to a data source.
- Monitor and optimize performance: Once your ETL job or data pipeline is running, you can monitor its performance and optimize it as needed. You can use the Glue ETL library and the Glue ETL job developer guide to optimize the performance of your ETL job or data pipeline.
Best Practices for optimizing AWS Glue Performance
Here are some best practices for optimizing the performance of AWS Glue:
Use the appropriate data format: Choose the appropriate data format for your data, such as CSV, JSON, Avro, or Parquet, based on the size and structure of your data. For example, Avro is a good choice for large, complex data sets, while CSV is a good choice for small, simple data sets.
Use partitioning and partition pruning: Use partitioning and pruning to prepare your ETL job or data pipeline performance. Partitioning divides your data into smaller chunks, which makes it easier to process and query. Partition pruning reduces the amount of data that is processed by your ETL job or data pipeline, which can improve its performance.
Use parallel processing: Use parallel processing to improve the performance of your ETL job or data pipeline. You can use the Glue ETL library and the Glue ETL job developer guide to enable parallel processing in your ETL job or data pipeline.
Use the Glue development endpoint: Use the Glue development endpoint to develop, debug, and test your ETL job or data pipeline before deploying it to production. This can help you identify and fix any issues before they affect your production environment.
Monitor and optimize resource usage: Monitor and optimize the resource usage of your ETL job or data pipeline to improve its performance. You can use the Glue ETL library and the Glue ETL job developer guide to optimize the resource usage of your ETL job or data pipeline.
Conclusion
AWS Glue is a fully managed ETL service that makes it easy to extract, transform, and load data between data stores in the cloud. It has a variety of features and benefits, including a fully managed service, data integration, data catalog, data classification, ETL jobs, and data pipelines. AWS Glue can be used in a variety of ETL scenarios, such as Data Lake integration, Data Warehouse integration, data migration, data preparation and stream processing.
To set up and use AWS Glue, you need to create an AWS Glue Data Catalog, connect to your data sources and targets, create an ETL job or data pipeline, set up scheduling and triggers, and monitor and optimize performance. By following the best practices for optimizing AWS Glue performance, you can improve the performance of your ETL job or data pipeline and get the most out of the cloud service. It is easy to use, secure, and cost-effective making it an ideal choice for businesses looking to move data quickly and securely.
If you are new to AWS Glue check out this tutorial 🙂
Here you can find more interesting articles.
Get some more tips on how to grant read access to all tables in AWS Glue Data Catalog.
https://kodlot.com/aws-lake-formation-grant-read-access-to-all-tables-in-aws-glue-data-catalog/